Use GPU Nodes
You can use GPU cloud hosts as cluster nodes in UK8s as follows:
Image Instructions
When using cloud host models with high cost performance graphics cards (such as high cost performance graphics cards 3, high cost performance graphics cards 5, high cost performance graphics cards 6) as nodes in UK8s cluster, you need to use the standard image Ubuntu 20.04 top-end.
- High cost performance graphics cards support availability zones
- North China(Wlcb)A
- East China(Shanghai2)B
- Beijing 2B
| Graphics Card | Image | Driver Version | CUDA Version |
|---|---|---|---|
| High cost performance graphics cards (High Cost Performance 3, High Cost Performance 5, High Cost Performance 6) | Ubuntu 20.04 High Value | 550.120 | 12.4 |
| Non-high cost performance graphics cards (such as T4, V100S, P40, etc.) | Ubuntu 20.04 | 550.90.12 | 12.4 |
| Non-high cost performance graphics cards (such as T4, V100S, P40, etc.) | Centos 7.6 | 450.80.02 | 11.0 |
Create a Cluster
When creating a cluster, in Node configuration, select the machine type as “GPU Type G”, and then select the specific GPU card type and configuration.
Note: If you choose a high cost performance graphics card, you need to use the standard image Ubuntu 20.04 high cost performance in node image.
Add Nodes
When adding a Node node to an existing cluster, select the machine type as “GPU Type G”, and then select the specific GPU card type and configuration.
Add Existing Hosts
Add the created GPU cloud host to an existing cluster, and choose the appropriate node image.
Instructions for Use
-
By default, containers do not share GPUs. Each container can request one or more GPUs. A small part of the GPU cannot be requested.
-
The Master node of the cluster does not currently support GPU models.
-
The standard image provided by UK8s has installed nvidia driver. In addition, the
nvidia-device-plugincomponent is installed by default in the cluster. After the GPU resources are added to the cluster, they can be automatically recognized and registered. -
How to verify the normal use of the GPU node:
-
Check if the node has the resource of
nvidia.com/gpu. -
Run the following example to request the NVIDIA GPU using the
nvidia.com/gpuresource type and check if the log result is correct.
$ cat <<EOF | kubectl apply -f - apiVersion: v1 kind: Pod metadata: name: gpu-pod spec: restartPolicy: Never containers: - name: cuda-container image: uhub.ucloud-global.com/uk8s/cuda-sample:vectoradd-cuda10.2 resources: limits: nvidia.com/gpu: 1 # requesting 1 GPU tolerations: - key: nvidia.com/gpu operator: Exists effect: NoSchedule EOF$ kubectl logs gpu-pod [Vector addition of 50000 elements] Copy input data from the host memory to the CUDA device CUDA kernel launch with 196 blocks of 256 threads Copy output data from the CUDA device to the host memory Test PASSED Done -
-
GPU Cloud Host NCCL TOPO File Passthrough to Pod
If NCCL performance testing in a GPU pod does not meet expectations, consider passthrough the topology.xml file from the virtual machine to the pod. The specific operations are as follows:
Prerequisites: The node is equipped with 8 high-cost-performance GPUs (e.g., High-Cost-Performance GPU 6, High-Cost-Performance GPU 6 Pro, A800, etc.).
Step 1: Verify Topology File Existence
Check if the virtualTopology.xml file exists in the path /var/run/nvidia-topologyd/ on the GPU node:
- If it exists, proceed to Step 2.
- If it does not exist, contact technical support to obtain the file. Copy the file to /var/run/nvidia-topologyd/virtualTopology.xml on the GPU node, then proceed to Step 2.
Step 2: Add Configuration to GPU Pod YAML
Add the following content to the gpu-pod.yaml file:
containers:
volumeMounts:
- mountPath: /var/run/nvidia-topologyd
name: topologyd
readOnly: true
volumes:
- name: topologyd
hostPath:
path: /var/run/nvidia-topologyd
type: Directory
Plugin Upgrade
Upgrade the nvidia-device-plugin to the latest version to address GPU node instability issues.
Upgrade Methods
- Method 1: Use kubectl set image to change the image version of the nvidia-device-plugin-daemonset to v0.14.1:
$ kubectl set image daemonset nvidia-device-plugin-daemonset -n kube-system nvidia-device-plugin-ctr=uhub.service.ucloud.cn/uk8s/nvidia-k8s-device-plugin:v0.14.1
daemonset.apps/nvidia-device-plugin-daemonset image updated- Method 2: Modify the yaml file of nvidia-device-plugin-daemonset:
- Execute the command:
$ kubectl edit daemonset nvidia-device-plugin-daemonset -n kube-system- Locate the spec.template.spec.containers.image field in the configuration to view the current image information:
- image: uhub.service.ucloud.cn/uk8s/nvidia-k8s-device-plugin:1.0.0-beta4- Update the image to uhub.service.ucloud.cn/uk8s/nvidia-k8s-device-plugin:v0.14.1 and save the changes.
UPHost Core Pinning
UPHost hosts now support core pinning by default, which improves GPU efficiency in certain scenarios.
To enable core pinning, delete the file /var/lib/kubelet/cpu_manager_state on the UPHost node and ensure the Kubelet is configured with the following parameters (refer to official documentation for Topology Manager Policy and CPU Manager Policy):
-cpu-manager-policy=static
--topology-manager-policy=best-effort Check if the node is configured with core pinning parameters by running:
ps -aux|grep kubelet|grep topology-manager-policy
Verify Core Pinning Success
- Preparations Before Creating a Test Pod
- Ensure that the CPU, Memory, and GPU quantities in limits and requests are consistent, and CPU values must be integers.
- Set spec.nodeName to the IP address of the UPHost to ensure the pod is scheduled to this node.
Now let’s create a Pod
apiVersion: v1
kind: Pod
metadata:
name: dcgmproftester
spec:
nodeName: "10.60.159.170" # Replace with the IP of the UPHost node
restartPolicy: OnFailure
containers:
- name: dcgmproftester12-1
image: uhub.service.ucloud.cn/uk8s/dcgm:3.3.0
command: ["/usr/bin/dcgmproftester12"]
args: ["--no-dcgm-validation", "-t 1004", "-d 3600"] # -d specifies runtime in seconds
resources: # Modify values based on the actual machine configuration
limits: ## Keep limits identical to requests
nvidia.com/gpu: 1
memory: 10Gi
cpu: 10
requests:
nvidia.com/gpu: 1
memory: 10Gi
cpu: 10
securityContext:
capabilities:
add: ["SYS_ADMIN"]-
After the Pod status becomes Running, log in to the bare metal node via ssh.
-
Enter the command crictl ps to get the list of containers on the current node. Find the ID of the container we just created according to the creation time or container name. Then enter the command crictl inspect
| grep pid to get the process pid. -
Enter the command taskset -c -p
to get the CPU affinity information:

We can see that the CPU affinity range of the Pod is 1-5, 65-69 instead of the full CPU list, proving that CPU pinning is successful.
- Now enter the command nvidia-smi to obtain GPU information and check GPU affinity:
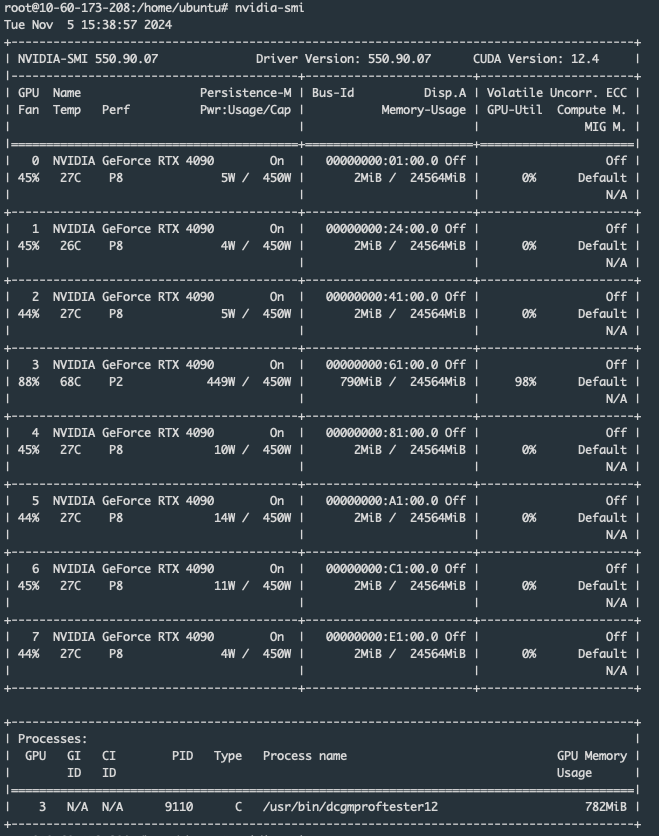
In the Process box of the above figure, it records which GPU is running. In the figure, GPU2 is running, proving that GPU binding is successful.
- Use the command nvidia-smi topo -m to check whether the GPU and CPU are on the same NUMA node:
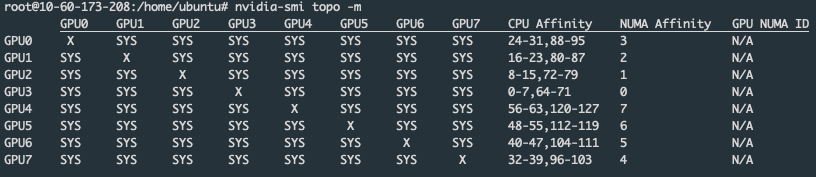
We can see that the CPU Affinity of GPU3 is 0-7,64-71. In step 4, the CPU Affinity list of the process we obtained is 1-5,65-69. This proves that the GPU and CPU correspond to the same NUMA node.
- Supplementary instructions for the Best-effort strategy:
When using the best-effort strategy, it is necessary to understand the configuration of the bare metal in advance to determine the parameter settings for the Pod to apply for CPU and GPU. For example, a bare metal cloud host has the following configuration:
| CPU | GPU | Memory (Does not affect core pinning) | Number of NUMA Nodes |
|---|---|---|---|
| 128 | 8 | 1024 | 8 |
CPU and NUMA parameters can be obtained by the command lscpu. GPU parameters can be obtained by the command nvidia-smi topo -m.
Through the command lscpu, we can know the relationship between NUMA nodes and CPU cores:
...
NUMA node0 CPU(s): 0-7,64-71
NUMA node1 CPU(s): 8-15,72-79
NUMA node2 CPU(s): 16-23,80-87
NUMA node3 CPU(s): 24-31,88-95
NUMA node4 CPU(s): 32-39,96-103
NUMA node5 CPU(s): 40-47,104-111
NUMA node6 CPU(s): 48-55,112-119
NUMA node7 CPU(s): 56-63,120-127
...We can learn the relationship between NUMA nodes and GPUs through the command nvidia-smi topo -m:
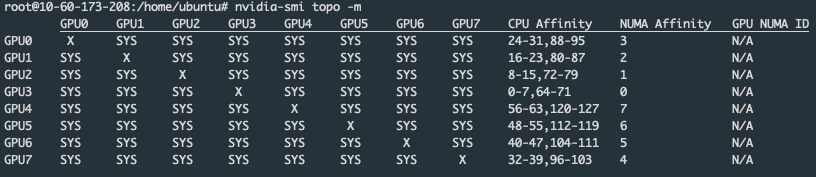
It can be seen that each NUMA node contains 16 CPU cores and 1 GPU. To ensure that both the CPU and GPU are affined to the same NUMA node, our configuration needs to ensure that the number of NUMA nodes affined by the GPU is equal to that affined by the CPU; otherwise, inconsistent affined nodes may result. The following are the situations where affinity can be achieved:
| GPU | CPU |
|---|---|
| 1 | 1 ~ 16 |
| n | > 16 * (n - 1) and ≤ 16 * n |
Here, 16 and 1 are obtained by checking the configuration using the method described above. The configurations of different machines are different, so you need to check them yourself.
Except for the above GPU/CPU ratios, other situations cannot achieve NUMA affinity.
For details, please refer to the official documentation.