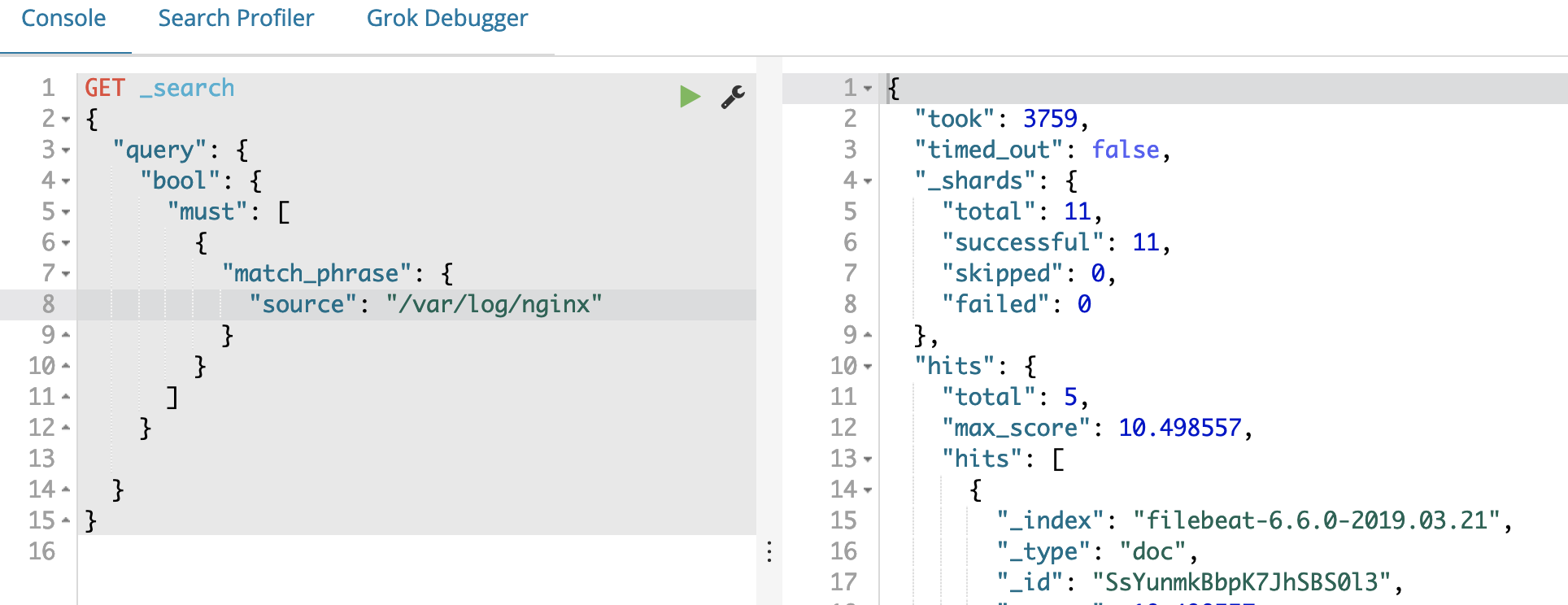
Building a UK8S Log Solution with ELK
Next, we’ll cover how to build a UK8S log solution using Elasticsearch, Filebeat, and Kibana.
I. Deploying Elasticsearch
1. About Elasticsearch
Elasticsearch (ES) is an open-source, distributed, RESTful full-text search engine built on Lucene. It is also a distributed document database where each field can be indexed and searched. ES can scale horizontally across hundreds of servers to store and process PB-level data, enabling fast storage, search, and analysis of large datasets. It is often used as the core engine for complex search scenarios.
2. Environment Requirements
When running Elasticsearch, the vm.max_map_count kernel parameter must be greater than 262144. Therefore, before starting, make sure this parameter has been adjusted correctly.
sysctl -w vm.max_map_count=262144You can also add an initContainer to the ES orchestration file to modify the kernel parameters, but this requires the kubelet to be started with the —allow-privileged parameter. The UK8S defaults to enabling this parameter. We’ll use the initContainer method in the examples to follow.
3. ES Node Roles
ES Nodes can be divided into several roles:
Master-eligible node is the node that is eligible to be selected as a Master node. Set node.master: true.
Data node is the node that stores data, set as node.data: true.
Ingest node is the node that processes data, set as node.ingest: true.
Trible node is used for cluster integration.
For a single-node Node, it defaults to master-eligible and data. For a multi-node cluster, the roles of each node need to be carefully planned based on needs.
4. Deploying Elasticsearch
To facilitate demonstration, we’ll place all object resources in a namespace called elk. So we’ll need to create a namespace first:
kubectl create namespace elkNo Distinction Between Node Roles
Under this mode, roles are not distinguished among nodes in the cluster. Please refer to the elk-cluster.yaml configuration file.
bash-4.4# kubectl apply -f elk-cluster.yaml
deployment.apps/kb-single created
service/kb-single-svc created
statefulset.apps/es-cluster created
service/es-cluster-nodeport created
service/es-cluster created
bash-4.4# kubectl get po -n elk
NAME READY STATUS RESTARTS AGE
es-cluster-0 1/1 Running 0 2m18s
es-cluster-1 1/1 Running 0 2m15s
es-cluster-2 1/1 Running 0 2m12s
kb-single-69ddfc96f5-lr97q 1/1 Running 0 2m18s
bash-4.4# kubectl get svc -n elk
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
es-cluster ClusterIP None <none> 9200/TCP,9300/TCP 2m20s
es-cluster-nodeport NodePort 172.17.177.40 <none> 9200:31200/TCP,9300:31300/TCP 2m20s
kb-single-svc LoadBalancer 172.17.129.82 117.50.40.48 5601:38620/TCP 2m20s
bash-4.4#Access Kibana via kb-single-svc’s EXTERNAL-IP.
Distinguishing Node Roles
If you need to distinguish the roles of the nodes, you need to set up two StatefulSet deployments - one for the Master cluster and one for the Data cluster. In the Data cluster storage example, an emptyDir is simply used. Depending on your needs, you can use localStorage or hostPath. For information about storage, refer to the Kubernetes official website . This method can prevent data loss and index rebuilding when a Data node restarts locally. However, if migration occurs, a shared storage solution is the only way to keep the data. The specific orchestration file can be found here: elk-role-cluster.yaml
bash-4.4# kubectl apply -f elk-role-cluster.yaml
deployment.apps/kb-single created
service/kb-single-svc created
statefulset.apps/es-cluster created
statefulset.apps/es-cluster-data created
service/es-cluster-nodeport created
service/es-cluster created
bash-4.4# kubectl get po -n elk
NAME READY STATUS RESTARTS AGE
es-cluster-0 1/1 Running 0 53s
es-cluster-1 1/1 Running 0 50s
es-cluster-2 1/1 Running 0 47s
es-cluster-data-0 1/1 Running 0 53s
es-cluster-data-1 1/1 Running 0 50s
es-cluster-data-2 1/1 Running 0 47s
kb-single-69ddfc96f5-lxsn8 1/1 Running 0 53s
bash-4.4# kubectl get statefulset -n elk
NAME READY AGE
es-cluster 3/3 2m
es-cluster-data 3/3 2m
bash-4.4# kubectl get svc -n elk
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
es-cluster ClusterIP None <none> 9200/TCP,9300/TCP 44s
es-cluster-nodeport NodePort 172.17.63.138 <none> 9200:31200/TCP,9300:31300/TCP 44s
kb-single-svc LoadBalancer 172.17.183.59 117.50.92.74 5601:32782/TCPII. Deploying FileBeat
In the process of log collection, Logstash comes to mind first because it’s an important member of the ELK stack. But during testing, we found that Logstash is based on JDK. Just starting Logstash without generating logs consumes about 500M of memory. In the case of starting a log collection component in each Pod, using Logstash seems to waste system resources. Therefore, we recommend the lightweight log collection tool Filebeat, which consumes only about 12M of memory when started separately. The specific orchestration file can be referred to as filebeat.yaml . This example uses DaemonSet for orchestration.
bash-4.4# kubectl apply -f filebeat.yaml
configmap/filebeat-config created
daemonset.extensions/filebeat created
clusterrolebinding.rbac.authorization.k8s.io/filebeat created
clusterrole.rbac.authorization.k8s.io/filebeat created
serviceaccount/filebeat createdThe configuration of filebeat used in the orchestration file is mounted to /home/uk8s-filebeat/filebeat.yaml. The actual startup of filebeat uses this custom configuration. For information about filebeat’s configuration, see the corresponding explanation in Configuring Filebeat .
The Filebeat command line parameters can be referred to Filebeat Command Reference . The parameters used in this example are explained as follows:
- -c, —c FILE
Specifies the configuration file used by Filebeat. If not specified, the default configuration file /usr/share/filebeat/filebeat.yaml is used.
- -d, —d SELECTORS
Enables the debug mode for the specified selectors. Selectors is a list separated by commas. -d ”*” means to debug all components. Please turn off this option in the actual production environment. It can be effectively debugged when the configuration is first switched on.
- -e, —e
Specifies that the log is output to standard error, and the default syslog/file output is turned off.
III. Deploying Logstash (Optional)
Since Filebeat’s message filtering capability is limited, it is usually combined with Logstash in actual production environments. In this architecture, Filebeat acts as a log collector, sending data to Logstash. After parsing and filtering by Logstash, it is sent to Elasticsearch for storage and presented to users by Kibana.
1. Creating Configuration Files
Create the configuration file of Logstash. You can refer to elk-log.conf. More detailed configuration information can be seen in Configuring Logstash . Most Logstash configuration files can be divided into 3 parts: input, filter, and output. The sample configuration file indicates that Logstash gets data from Filebeat and outputs it to Elasticsearch.
2. Create a ConfigMap named elk-pipeline-config based on the configuration file as follows:
bash-4.4# kubectl create configmap elk-pipeline-config --from-file=elk-log.conf --namespace=elk
configmap/elk-pipeline created
bash-4.4# kubectl get configmap -n elk
NAME DATA AGE
elk-pipeline-config 1 9s
filebeat-config 1 21m3. Deploy Logstash on K8S cluster.
Write logstash.yaml, and mount the ConfigMap created in the yaml file. It’s important to note that the logstash-oss image is used here. For the differences between the OSS and non-OSS versions, please refer to this link .
bash-4.4# kubectl apply -f logstash.yaml
deployment.extensions/elk-log-pipeline created
service/elk-log-pipeline created
bash-4.4# kubectl get po -n elk
NAME READY STATUS RESTARTS AGE
elk-log-pipeline-55d64bbcf4-9v49w 1/1 Running 0 50m4. Check if Logstash is working correctly. If the following content appears, it means Logstash is working normally
bash-4.4# kubectl logs -f elk-log-pipeline-55d64bbcf4-9v49w -n elk
[2019-03-19T08:56:03,631][INFO ][logstash.agent ] Successfully started Logstash API endpoint {:port=>9600}
...
[2019-03-19T08:56:09,845][INFO ][logstash.inputs.beats ] Beats inputs: Starting input listener {:address=>"0.0.0.0:5044"}
[2019-03-19T08:56:09,934][INFO ][logstash.pipeline ] Pipeline started succesfully {:pipeline_id=>"main", :thread=>"#<Thread:0x77d5c9b5 run>"}
[2019-03-19T08:56:10,034][INFO ][org.logstash.beats.Server] Starting server on port: 50445. Modify the output parameter of filebeat.yaml to point the output to Logstash
items:
- apiVersion: v1
kind: ConfigMap
metadata:
...
data:
filebeat.yml: |
...
output.logstash:
hosts: ["elk-log-pipeline:5044"]
...IV. Collecting Application Logs
We’ve deployed Filebeat to collect application logs and output the collected logs to Elasticsearch. Now we’ll use an Nginx application as an example to test whether the logs can be collected, indexed, and displayed properly.
1. Deploying Nginx Application
Create a deployment and LoadBalancer service for Nginx. This way, Nginx can be accessed via EIP. We mount the output path of the Nginx access log to the host’s /var/log/nginx/ path using hostPath.
bash-4.4# kubectl apply -f nginx.yaml
deployment.apps/nginx-deployment unchanged
service/nginx-cluster configured
bash-4.4# kubectl get svc -n elk nginx-cluster
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
nginx-cluster LoadBalancer 172.17.153.144 117.50.25.74 5680:48227/TCP 19m
bash-4.4# kubectl get po -n elk -l app=nginx
NAME READY STATUS RESTARTS AGE
nginx-deployment-6c858858d5-7tcbx 1/1 Running 0 36m
nginx-deployment-6c858858d5-9xzh8 1/1 Running 0 36m2. Filebeat Configuration
When Filebeat was deployed before, /var/log/nginx/ was added to inputs.paths, so Filebeat can monitor and collect nginx logs.
filebeat.modules:
- module: system
filebeat.inputs:
- type: log
paths:
- /var/log/containers/*.log
- /var/log/messages
- /var/log/nginx/*.log
- /var/log/*
symlinks: true
include_lines: ['hyperkube']
output.logstash:
hosts: ["elk-log-pipeline:5044"]
logging.level: info
index: filebeat-3. Access the Nginx service through the public network to generate access logs
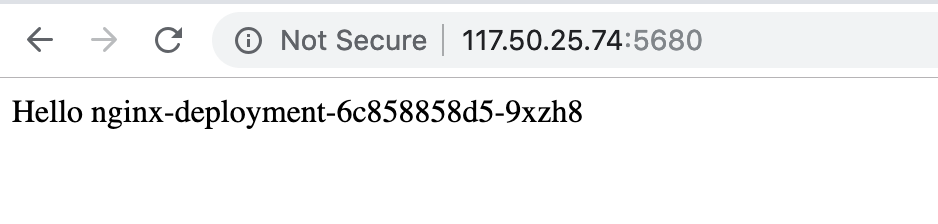
4. Check Log Capture Status through Kibana