Quick Deployment of LLaMA2 Model
Introduction
The LLaMA2 model has undergone more extensive and in - depth training, with a larger number of tokens and a longer context length. Compared to LLaMA1, LLaMA2 has been trained with 2 trillion tokens, and its context length is twice that of LLaMA1. In addition, the LLaMA - 2 - chat model has been trained with over 1 million new human annotations. The training corpus of the LLaMA2 model is richer than that of LLaMA1, with 40% more data. Its context length has been upgraded from 2048 to 4096, which enables it to understand and generate longer texts, providing better support for more complex tasks. In the pre - training data, the language distribution is greater than or equal to 0.005%, but most of the data is in English, so LLaMA2 performs best in English use cases. If you want to use LLaMA2 for copywriting planning in Chinese scenarios, you need to conduct Chinese - enhancement training to make it perform better in handling Chinese texts.
Quick Deployment
Log in to the XXXCloud console (https://console.ucloud-global.com/uhost/uhost/create ) Select “GPU Type” and “V100S” for the instance type, and choose detailed configurations such as the number of CPUs and GPUs as needed.
Minimum recommended configuration: 10-core CPU, 64GB memory, and 1 V100S GPU.
Select “Image Market” for the image, search for “LLaMA2” in the image name, and select this image to create the GPU UHost.
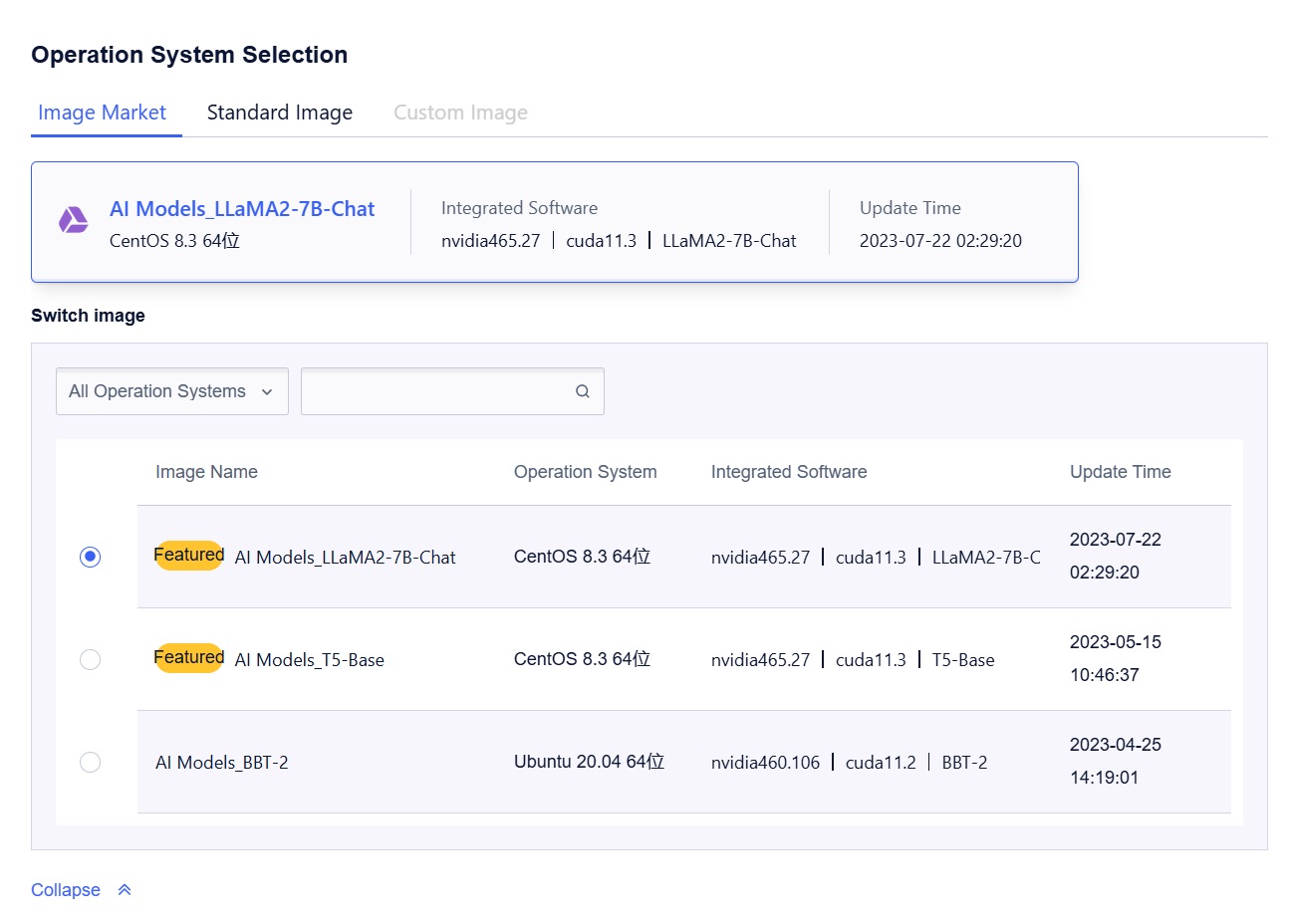
Once the GPU UHost is successfully created, log in to the GPU UHost.